Dataset¶
Contents
Introduction¶
Dataset manages a collection of cues, implements the Cue Collection and adds support for flexible and efficient cue modification and lookup, even for large volumes of cues. Cues are simple Javascript objects:
let cue = {
key: "mykey",
interval: new Interval(2.2, 4.31),
data: {...}
}
Dataset maps keys to cues, like a Map. In addition, cues
are also indexed by their positioning on the timeline (see Interval), allowing efficient search along the timeline. For instance, the lookup method returns all cues within a given lookup interval.
Dataset is useful for management and visualization of large datasets with timed data, represented as cues. Typical examples of timed data include log data, user comments, sensor measurements, subtitles, images, playlists, transcripts, gps coordinates etc.
Furthermore, the dataset is carefully designed to support precisely timed playback of timed data. This is achieved by connecting one or more Sequencers to the Dataset.
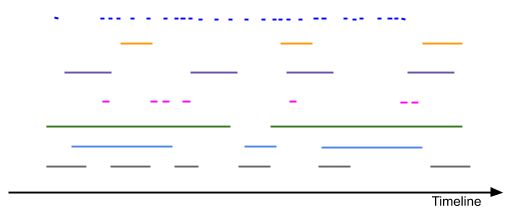
This illustrates multiple tracks (different colors) of timed data. Each colored line segment is a cue, with horizontal placement and length indicating cue validity in reference to the timeline. Tracks may simply be different types of cues, e.g. comments, gps-coordinates, videos, images, audio snippets, etc. A single dataset may hold all kinds of cues, collectively defining the state of a media presentation, see Linear Media State.
Example¶
// create dataset
let ds = new Dataset();
// timed data
let subtitles = [
{
id: "1234",
start: 123.70,
end: 128.21,
text: "This is a subtitle"
},
...
];
// create cues from subtitles data
let cues = subtitles.map(function (sub) {
let itv = new Interval(sub.start, sub.end);
return {key: sub.id, interval: itv, data: sub};
});
// insert cues
ds.update(cues);
// lookup cues
let result_cues = ds.lookup(new Interval(120, 130));
// delete cues
ds.update(cues.map(function(cue) {
return {key: cue.key};
});
Update¶
Dataset provides a single operation update(cues) allowing cues to be inserted, modified and/or deleted. The argument cues defines a list of cue arguments (or a single cue argument) to be inserted into the dataset. If a cue with identical key already exists in the dataset, the pre-existing cue will be modified to match the provided cue argument. If a cue argument includes a key but no interval and no data, this means to delete the pre-existing cue.
let ds = new Dataset();
// insert
ds.update({
key: "key1",
interval: new Interval(2.2, 4.31),
data: "foo"
});
// modify
ds.update({
key: "key2",
interval: new Interval(4.4, 6.9, false, false),
data: "bar"
});
// delete
ds.update({key: "mykey"})
For convenience, intervals in cue arguments may also be specified as an array, leaving it to the dataset to create Interval objects for internal use. Also, addCue and removeCue methods provide shorthand access to update. For instance, the above code example may be rewritten as follows:
let ds = new Dataset(); ds.addCue("key1", [2.2, 4.31], "foo"); ds.addCue("key2", [4.4, 6.9, false, false], "bar");
See also Update Convenience Methods for more details.
Cue Management¶
When a cue is inserted into the dataset, it will be managed until it is deleted at some later point. All cue access operations (e.g. cues, lookup) provide direct access to managed cues.
Warning
Cues managed by dataset are considered immutable and must never be modified directly by application code. Always use the update operation to implement cue modification.
If managed cue objects are modified by external code, no guarantees can be given concerning functional correctness. By default, the dataset does not offer any protection against external cue modification. However, in safe mode Object.freeze() is applied to all cues, implying that attempted modification should throw an exception (strict mode). This is useful for evaluation but should likely be turned off in production, as use of Object.freeze() comes with a performance penalty.
let ds = new Dataset({safe:true})
Important
- always create cue arguments as new objects with desired state
- never reuse managed cue objects as arguments to update
The dataset will throw an exception if a currently managed cue object is used as cue argument with the update operation.
Unwanted modifications of managed cues may also occur if the cue.data property is subject to external modification. Object.freeze() does not protect against this. For instance, the data object may a reference to an object which is managed by an application specific data model. If this is the case one approach would be to copy data objects as part of cue creation. Another approach is to add one level of indirection, adding only immutable object id’s to the dataset. This though would imply that data changes can not be detected by the dataset.
Cue Arguments¶
Dataset also supports partial cue modification. Partial modification means to modify only the cue interval property or only the cue data property. For convenience, partial cue modification allows this to be done without restating the unmodified part of the cue. Partial cue modification is specified simply by omitting the property which is not to be replaced. The omitted property will then be preserved from the pre-existing cue. This yields four types of legal cue arguments for the update operation:
| Type | Cue argument | Text |
|---|---|---|
| A | {key: “mykey”} | no interval, no data |
| B | {key: “mykey”, interval: …} | interval, no data |
| C | {key: “mykey”, data: …} | no interval, data |
| D | {key: “mykey”, interval: …, data: …} | interval, data |
Note
Note that {key: "mykey"} is type A whereas {key: "mykey",
data:undefined} is type C. The type evaluation is based on
cue.hasOwnProperty("data") rather than cue.data ===
undefined. This ensures that undefined may be used as a data
value with cues.
Similarly, cue intervals may also take the value undefined.
Without an interval cues become invisible to the lookup
operation, yet still accessible through Map operations
has, get, keys, values, entries. Otherwise, if cue interval is
defined, it must be an instance of the Interval class.
Note
Cue intervals are often derived from timestamps which are also part of cue data. This implies that inconsistency may be introduced, if the interval is changed, without also changing the associated timestamps in the data property – or the other way around.
Though not criticial for the integrity of the dataset, such inconsistencies might be confusing for users. For instance if timeline playback does not match timestamps in cue data.
Rule of thumb:
- Avoid cue type B modification if timestamps are part of data.
- Similarly, avoid type C modification of timestamps in data, if cue intervals are derived from these timestamps.
In summary, the different types of cue arguments are interpreted according to the following table.
| Type | Cue NOT pre-existing | Cue pre-existing |
|---|---|---|
| A | NOOP | DELETE cue |
| B | INSERT interval, data undefined | MODIFY interval, PRESERVE data |
| C | INSERT data, interval undefined | MODIFY data, PRESERVE interval |
| D | INSERT cue | MODIFY cue |
Cue Equality¶
Cue modification has no effect if cue argument is equal to the pre-existing cue. The dataset will detect equality of cue intervals and avoid unneccesary reevaluation of internal indexes. However, the definition of object equality for cue data may be application dependent. For this reason the update operation allows a custom equality function to be specified using the optional parameter equals. Note that the equality function is evaluated with the cue data property as arguments, not the entire cue.
function equals(a, b) {
...
return true;
}
ds.update(cues, {equals:equals});
The default equality function used by the dataset is the following:
function equals(a, b) {
// Create arrays of property names
let aProps = Object.getOwnPropertyNames(a);
let bProps = Object.getOwnPropertyNames(b);
let len = aProps.length;
let propName;
// If properties lenght is different => not equal
if (aProps.length != bProps.length) {
return false;
}
for (let i=0; i<len; i++) {
propName = aProps[i];
// If property values are not equal => not equal
if (a[propName] !== b[propName]) {
return false;
}
}
// equal
return true;
}
Given that object equality is appropriately specified, update operations may safely be repeated, even if cue data have not changed. For instance, this might be the case when an online source of timed data is polled repeatedly for updates. Results from polling may then be forwarded directly to the update operation. The return value will indicate if any actual modifications occured.
Update Result¶
The update operation returns an array of items describing the effects for each cue argument. Result items are identical to event arguments eArg defined in Event Argument.
// update result item
let item = {key: ..., new: {...}, old: {...}}
- key
- Unique cue key
- old
- Cue before modification, or undefined if cue was inserted.
- new
- Cue after modification, or undefined if cue was deleted.
It is possible with result items where both item.new and item.old are undefined. For instance, this will be the case if a cue is both inserted and deleted as part of a single update operation (see Batch Operations).
Batch Operations¶
The update() operation is batch-oriented, implying that multiple cue operations can be processed as one atomic operation. A single batch may include a mix of insert, modify and delete operations.
let ds = new Dataset();
let cues = [
{
key: "key_1",
interval: new Interval(2.2, 4.31),
data: "foo"
},
{
key: "key_2",
interval: new Interval(4.4, 6.9),
data: "bar"
}
];
ds.update(cues);
Batch oriented processing is crucial for the efficiency of the update operation. In particular, the overhead of reevaluating internal indexes may be paid once for the accumulated effects of the entire batch, as opposed to once per cue modification.
Warning
Repeated invocation of update within a single processing task is an anti-pattern with respect to performance! Cue operations should if possible be aggregated and applied together as a single batch.
// cues
let cues = [...];
// NO!
cues.forEach(function(cue)) {
ds.update(cue);
}
// YES!
ds.update(cues);
Cue Chaining¶
It is possible to include several cue arguments concerning the same key in a single batch to update. This is called chained cue arguments. Chained cue arguments will be applied in the given order, and the net effect in terms of cue state will be equal to the effect of splitting the cue batch into individual invokations of update. Internally, chained cue arguments are collapsed into a single cue operation with the same net effect. For instance, if a cue is first inserted and then deleted within a single batch, the net effect is no effect.
Correct handling of chained cue arguments introduces an extra test within the update operation, possibly making it slightly slower for very large cues batches. If the cue batch is known to not include any chained cue arguents, this may be indicated by setting the option chaining to false. The default value for chaining is true.
ds.update(cues, {chaining:false});
Warning
If the chaining option is set to false, but the cue batch still contains chained cue arguments, this violation will not be detected. The consequences are not grave. The old value of result items and event arguments will be incorrect for chained cues.
Update Convenience Methods¶
The dataset defines a few convenience methods for updating the dataset implemented on top of the basic update primitive. Single cue operations addCue for inserting or modifying a cue and removeCue to delete a cue. These operations support Batch Operations through repeated invocation. Cue arguments will be buffered by an internal builder object and submitted as a single update operation on the dataset, just after the current JS task has completed. The result from the update operation is availble on a updateDone promise.
ds
.addCue("key_1", new Interval(1,2), data)
.removeCue("key_2")
.addCue("key_1", new Interval(1,3), data);
ds.updateDone.then((result) => {console.log(result)});
Note
Once resolved, the updateDone promise is replaced by a new promise for the next update operation, but still available on the same updateDone property. So, for later update results just access the updateDone getter property again.
function show_result(update_result) {
console.log("update result");
}
ds.updateDone.then(show_result);
ds.addCue("k", new Interval(612, 10000), "k")
setTimeout(() => {
ds.addCue("l", new Interval(614, 10000), "l");
ds.updateDone.then(show_result);
}, 1000);
To specify options for Batch Operations use a custom builder object.
let options;
let builder = ds.makeBuilder(options);
builder.updateDone.then(()=>{console.log("result")});
builder
.addCue("key_1", new Interval(1,2), data);
.removeCue("key_2");
.clear();
Tip
For interactive use _addCue and _removeCue avoid buffering cue arguments by using the update primitive directly.
let update_result = ds._addCue("key_1", new Interval(1,2), data);
Lookup¶
The operation lookup(interval, mask) identifies all cues matching a specific interval on the timeline. The parameter interval specifices the target interval and mask defines what interval relations count as a match, see Interval Match. Similarly, dataset provides an operation lookup_delete(interval, mask) which deletes all cues matching a given interval. This operation is more efficient than lookup followed by cue deletion using update.
Lookup endpoints¶
In addition to looking up cues, dataset also supports looking up cue endpoints. The operation lookup_endpoints(interval) identifies all cue endpoints inside the given interval, as defined in Interval Comparison. The operation returns a list of (endpoint, cue) pairs, where endpoint is the low or the high endpoint of the cue interval.
{
endpoint: [value, high, closed, singular],
cue: {
key: "mykey",
interval: new Interval(...),
data: {...}
}
}
The endpoint property is defined in Endpoint Types.
Events¶
Dataset supports three events batch, change and remove, as defined in Cue Collection.
Performance¶
The dataset implementation targets high performance with high volumes of cues. In particular, the efficiency of the lookup operation is important as it is used repeatedly during media playback. The implementation is therefor optimized with respect to fast lookup, with the implication that internal costs related to indexing are paid by the update operation.
The lookup operation depends on a sorted index of cue endpoints, and
sorting is performed as part of the update operation. For this
reason, update performance is ultimately limited by sorting
performace, i.e. Array.sort(), which is O(NlogN) (see sorting
complexity). Importantly, support for batch operations
reduces the sorting overhead by ensuring that sorting is
needed only once for a each batch operation, instead of repeatedly for
every cue argument. The implementation of lookup uses binary search
to identify the appropriate cues, yielding O(logN)
performance. The crux of the lookup algorithm is to resolve the cues
which COVERS (see :ref:’interval-comparison’) the lookup interval in sub linear time.
To indicate the performance metrics of the dataset, some measurements have been collected for common usage patterns. For this particular test a standard laptop computer is used (Lenovo ThinkPad T450S, 4 cpu Intel Core i5-53000 CPU, Ubuntu 18.04). Tests are run with Chrome and Firefox, with similar results. Though results will vary between systems, these measurements should at least give a rough indication.
Update performance depends primarily the size of the cue batch, but also a few other factors. The update operation is more efficient if the dataset is empty ahead of the operation. Also, since the update operation depends on sorting internally, it matters if the cues are mostly sorted or random order.
Tests operate on cue batches of size 100.000 cues, which corresponds to 200.000 cue endpoints. Results are given in milliseconds.
| INSERT | 100.000 sorted cues into empty dataset | 278 |
| INSERT | 100.000 random cues into empty dataset | 524 |
| INSERT | 100.000 sorted cues into dataset with 100.000 cues | 334 |
| INSERT | 100.000 random cues into dataset with 100.000 cues | 580 |
| INSERT | 10 cues into dataset with 100.000 cues | 2 |
| LOOKUP | 100.000 endpoints in interval from dataset of 100.000 cues | 74 |
| LOOKUP | 20 endpoints from dataset with 100.000 cues | 1 |
| LOOKUP | 50.000 cues in interval from dataset of 100.000 cues | 80 |
| LOOKUP | 10 cues in interval from dataset of 100.000 cues | 1 |
| LOOKUP_DELETE | 50.000 cues in interval from dataset with 100.000 cues | 100 |
| LOOKUP_DELETE | 10 cues in interval from dataset with 100.000 cues | 1 |
| DELETE | 50.000 random cues from dataset with 100.000 cues | 280 |
| DELETE | 10 random cues from dataset with 100.000 cues | 10 |
| CLEAR | Clear dataset with 100.000 cues | 29 |
The results show that the dataset implementation is highly efficient for lookup operations and update operations with modest cue batches, even if the dataset is preloaded with a large volume of cues (100.000). In addition, (not evident from this table) update behaviour is tested up to 1.000.000 cues and appears to scale well with sorting costs. However, batch sizes beyond 100.000 are not recommended, as this would likely hurt the responsiveness of the webpage too much. To maintain responsiveness it would make sense to divide the batch in smaller parts and spread them out in time. Use cases requiring loading of over 100.000 cues might also be rare in practice.